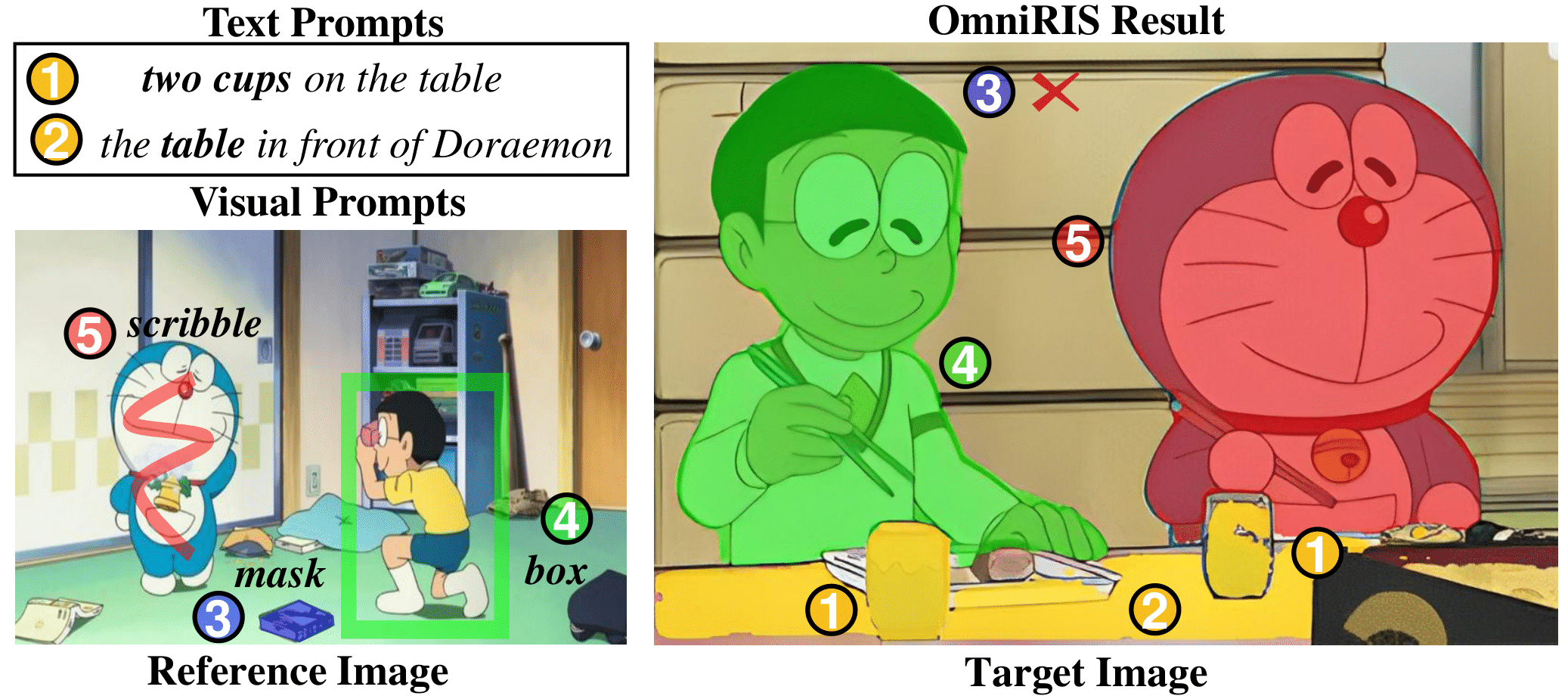
In this paper, we propose a novel task termed Omni-Referring Image Segmentation (OmniRIS) towards highly generalized image segmentation. Compared with existing unimodally conditioned segmentation tasks, such as RIS and visual RIS, OmniRIS supports the input of text instructions and reference images with masks, boxes or scribbles as omni-prompts. This property makes it can well exploit the intrinsic merits of both text and visual modalities, i.e., granular attribute referring and uncommon object grounding, respectively. Besides, OmniRIS can also handle various segmentation settings, such as one v.s. many and many v.s. many, further facilitating its practical use. To promote the research of OmniRIS, we also rigorously design and construct a large dataset termed OmniRef, which consists of 186,939 omni-prompts for 30,956 images, and establish a comprehensive evaluation system. Moreover, a strong and general baseline termed OmniSegNet is also proposed to tackle the key challenges of OmniRIS, such as omni-prompt encoding.
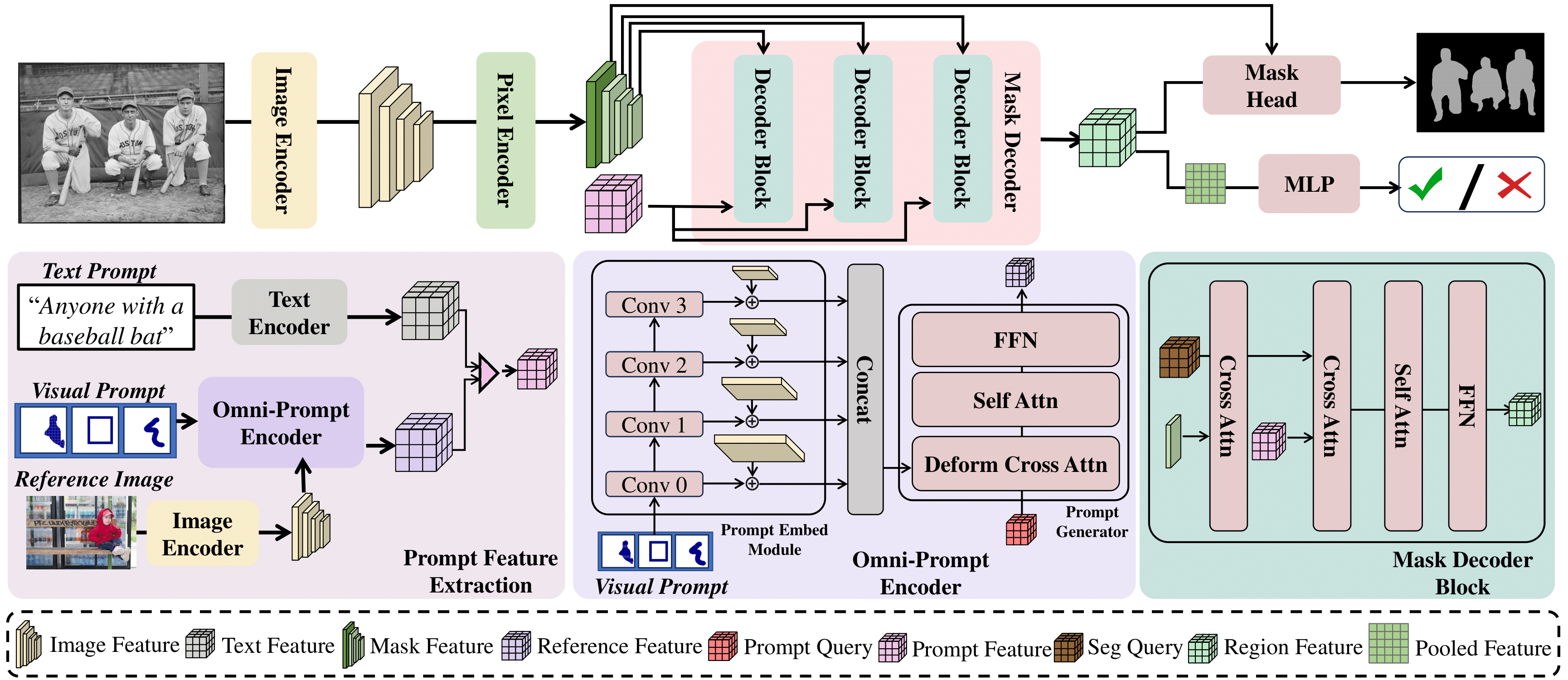
We propose a strong baseline, OmniSegNet, equipped with a novel Omni-Prompt Encoder to handle multi-modal inputs and a specific training regime for complex segmentation settings.
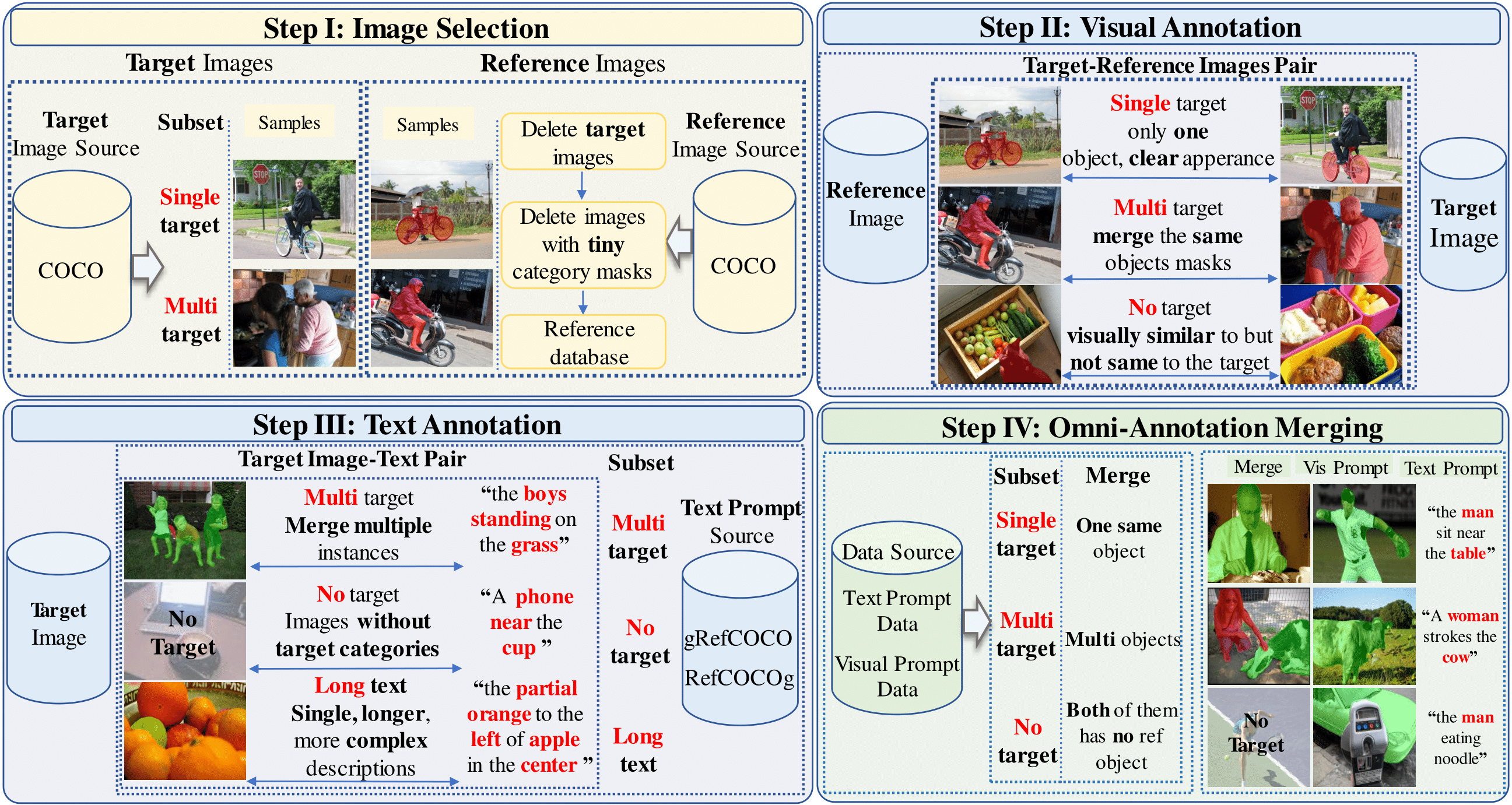
OmniRef is a large-scale benchmark with 186,939 omni-prompts over 30,956 images, supporting text, mask, box, and scribble prompts, and covering single-target, multi-target, and no-target segmentation scenarios.
@article{zheng2025omni,
title={Omni-Referring Image Segmentation},
author={Zheng, Qiancheng and Shen, Yunhang and Luo, Gen and Song, Baiyang and Sun, Xing and Sun, Xiaoshuai and Zhou, Yiyi and Ji, Rongrong},
journal={arXiv preprint arXiv:2512.06862},
year={2025}
}